本文共 14019 字,大约阅读时间需要 46 分钟。
本节书摘来自异步社区《CCIE路由和交换认证考试指南(第5版) (第2卷)》一书中的第1章,第1.4节构建IP路由表,作者 【美】那比克 科查理安(Narbik Kocharians) , 特里 文森(Terry Vinson) , 瑞克 格拉齐亚尼(Rick Graziani),更多章节内容可以访问云栖社区“异步社区”公众号查看
1.4 构建IP路由表
到目前为止,本章已经解释了如何构建BGP邻居关系、如何将路由注入到BGP表中以及BGP路由器如何选择将哪些路由宣告给邻居路由器等内容。有些内容与BGP选择去往每个前缀的最佳路由的BGP决策进程有关,在特定路由成为最佳路由之前还必须满足一个附加约束条件,那就是NEXT_HOP必须可达。本节将解释实现BGP终极目标(向IP路由表添加恰当的路由)的最后一步。虽然简单来说,就是BGP为每个前缀选择已识别的最佳BGP路由并将这些路由添加到IP路由表中,但是该过程需要满足一些约束条件,主要与AD(针对eBGP和iBGP路由)以及BGP同步(仅针对iBGP路由)有关。本节将详细讨论这些约束条件。
1.4.1 将eBGP路由添加到IP列表中
Cisco IOS软件在确定将哪些eBGP路由添加到IP路由表中时的规则很简单,只要满足以下两个条件即可:关键
BGP表中的eBGP路由是“最佳”路由;
如果从其他IGP或静态路由学到相同的前缀,那么BGP外部路由的AD必须小于其他路由源的AD。在默认情况下,Cisco IOS认为eBGP路由的AD值为20,因而eBGP路由的AD优于(小于)其他动态路由协议的默认AD(EIGRP汇总路由除外,其AD 值为5)。之所以会有这样的默认值,是因为从BGP学到的路由不应该是来自AS内部的前缀。虽然在正常情况下很少将学自eBGP的前缀视为学自IGP的路由,但如果确实如此,那么将默认优选BGP路由。BGP为eBGP路由、iBGP路由以及本地(本地注入的)路由设置不同的AD,这三类路由的默认AD值分别为20、200和200。利用以下两种方法可以更改默认AD(有关这两种方法的详细内容请参考第9章的AD部分):
利用BGP子命令distance bgp external-distance internal-distance local-distance设置从eBGP学到的前缀的AD、从iBGP学到的前缀的AD以及本地注入的前缀的AD;
利用BGP子命令distance distance { ip-address { wildcard-mask }} [ ipstandard-list | ip-extended-list ]更改AD。对于BGP来说,IP地址及子网掩码指的是为指定邻居配置的neighbor命令中使用的IP地址,而不是该路由的BGP RID或NEXT_HOP。ACL负责检查从邻居接收到的BGP路由,并为所有与该ACL允许语句相匹配的路由分配指定的AD值。关键
最后,需要对添加到IP路由表中的实际IP路由做进一步解释。该路由包含的前缀、前缀列表以及下一跳IP地址与BGP表列出的完全相同(即使NEXT_HOP PA不是直连网络中的IP地址),因而IP转发进程可能需要执行递归查询。例1-12给出了相应的配置示例,例中的R3拥有三条BGP路由,每条BGP路由的下一跳地址均为1.1.1.1,该地址正是R1的环回接口地址。从图1-4可以看出,R3与R1之间没有公共接口,去往1.1.1.1的路由列出了实际的下一跳IP地址(数据包将被转发到该地址)。
例1-12 R3的下一跳为1.1.1.1的路由,需要递归路由查询
! Packets forwarded to 31.0.0.0/8 match the last route, with next-hop 1.1.1.1; R3! then finds the route that matches destination 1.1.1.1 (the first route), finding! the appropriate next-hop IP address and outgoing interface.R3# show ip route | incl 1.1.1.1D 1.1.1.1 [90/2809856] via 10.1.23.2 , 04:01:44, Serial0/0/1B 32.1.1.0/24 [200/156160] via 1.1.1.1, 00:01:00B 32.0.0.0/8 [200/0] via 1.1.1.1, 00:01:00B 31.0.0.0/8 [200/156160] via 1.1.1.1 , 00:01:00
1.4.2 后门路由
eBGP路由默认AD值(20)较低对于某些拓扑结构来说可能会产生一定的问题(如图1-6所示),图中的企业1通过eBGP路由到达企业2的网络99.0.0.0,但这两个企业希望使用从OSPF学到的路由经企业间专线进行通信。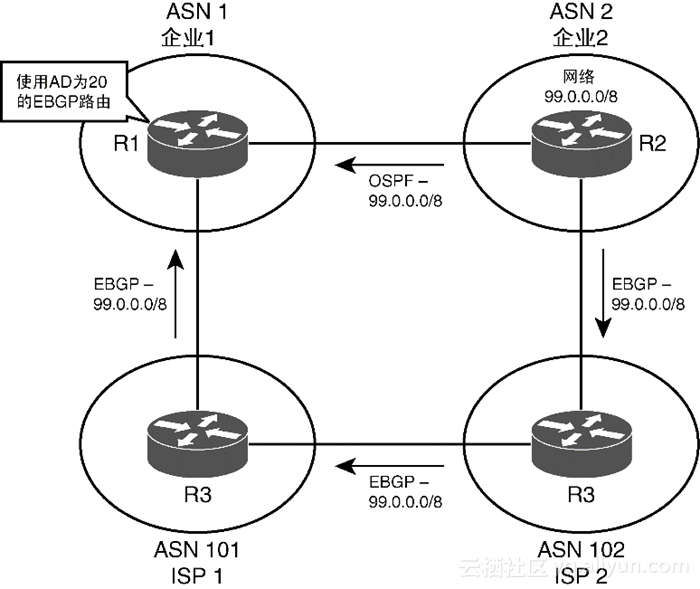
由于eBGP路由的AD(20)小于OSPF路由的AD(110),因而R1使用其eBGP路由去往99.0.0.0。此时一种解决方式是配置distance命令以减小OSPF路由的AD值,但BGP为此类场景提供了更好的解决方案,即使用network backdoor命令。对于本例来说,如果R1配置了路由器BGP子命令network 99.0.0.0 backdoor,那么将会达到如下效果:
R1将为从eBGP学到的到达网络99.0.0.0的路由使用本地AD(默认200);
R1不通过BGP宣告网络99.0.0.0。按照该解决方案,如果R1需要使用该私有链路去往企业2,那么就可以为每条前缀都配置network backdoor命令。如果去往每条前缀的OSPF路由都处于正常运行状态,那么R1将优选OSPF路由(AD为110),而不会选择从eBGP学到的经Internet的路由(AD为20)。如果OSPF路由丢失,那么这两个企业仍然能够通过Internet进行通信。1.4.3 向IP路由表添加iBGP路由
对于Cisco IOS来说,将iBGP路由添加到IP路由表也要满足与eBGP路由相同的两个条件:该路由必须是最佳BGP路由;
与其他路由源相比(根据AD进行比较),该路由必须是最佳路由。此外,对于从iBGP学到的路由来说,IOS还要考虑BGP同步问题。如果使用no synchronization命令禁用了BGP同步机制,那么将iBGP路由添加到IP表中与将eBGP路由添加到IP列表中的处理方式完全相同。如果启用了BGP同步机制(配置了BGP子命令synchronization),那么就可以避免出现一些IP路由问题。从图1-7可以看出,ASN 678错误地禁用了BGP同步机制,从而产生了路由黑洞。
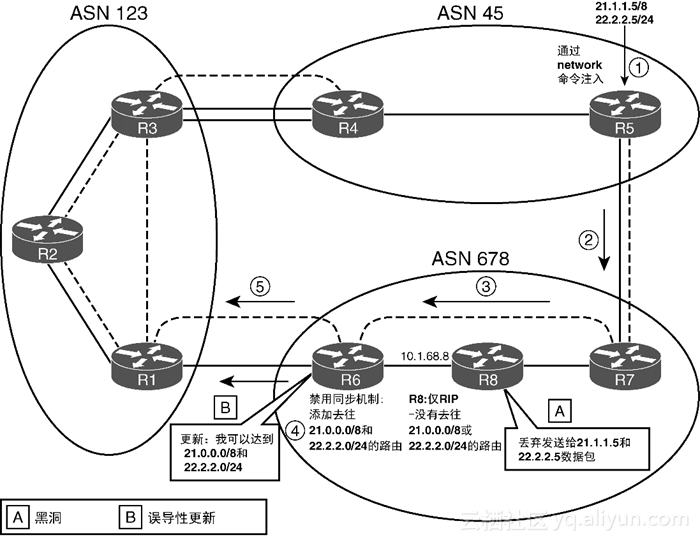
下面列出了图1-7中的BGP处理过程。
第1步:R5通过两条network命令将两条前缀(21.0.0.0/8和22.2.2.0/24)添加到自己的BGP表中。
第2步:R5将这两条前缀宣告给R7,但R7并没有将这些前缀重分发到自己的IGP中。
第3步:R7将这两条前缀宣告给R6。
第4步:由于R6(禁用了BGP同步)认为这些路由是“最佳”路由,因而R6将这些路由添加到自己的IP路由表中。
第5步:R6将这两条前缀宣告给R1。
上述过程出现了两个路由问题(如图中标示的A、B)。首先是路由黑洞问题(标示为A),出现路由黑洞的原因是R8没有去往BGP宣告的这两条前缀的路由,R8没有运行BGP(对于不与eBGP对等体直连的路由器来说很常见),R7也没有将这两条前缀重分发到IGP中,因而R8无法为这些前缀路由数据包。因此,虽然R6(可能还包括AS 123中的路由器)试图通过AS 678来转发去往这两条前缀的数据包,但R8却丢弃了这些数据包(因为路由黑洞)。
第二个路由问题(标示为B)出现在第5步,由于R6向其他AS(AS 123)宣称其能够到达这些前缀,从而进一步加剧了路由黑洞问题。R6认为其BGP表中去往21.0.0.0/8和22.2.2.0/24的路由是最佳路由,因而R6将这些路由宣告给R1。根据拓扑结构以及PA设置情况,R1会将这些路由视为最佳路由,从而将去往这些前缀的数据包发送给AS 678。但是根据前面的示例配置,R1应该将经R3去往AS 45的AS_PATH视为最佳路径。
虽然可以采用多种方案解决上述路由问题,但所有解决方案归根结底都必须让内部路由器(如R8)学到去往这些前缀的路由,从而解决路由黑洞以及宣告这些路由所带来的负面影响。针对这类问题的最原始解决方案是使用BGP同步并将BGP路由重分发到IGP中,不过目前可以提供两种更好的解决方案。
BGP路由反射器;
BGP联盟。有关这两种解决方案的详细信息将在后面的章节进行讨论。1.使用BGP同步并重分发路由
理解BGP同步的最好方式是结合希望使用该机制的场景进行分析。顾名思义,BGP同步就是将BGP路由重分发到IGP中,目前的ISP很少使用该方法,主要原因是担心将大量BGP路由注入到IGP中。但是将BGP同步与重分发结合使用,就可以解决与上述路由黑洞相关的故障问题。关键
理解BGP同步的关键就是必须知道重分发解决的是路由黑洞问题,而BGP同步解决的是将黑洞路由宣告到其他AS中的问题。例如,为了解决上述路由黑洞问题,R7需要将这两条前缀重分发到RIP中(如图1-7所示),此时R8就拥有了去往这些前缀的路由,从而解决了路由黑洞问题。
R6的同步特性处理的是上述路由问题的第二个问题,要求R6在特定条件下才能将这些前缀宣告给其他eBGP对等体(如R1)。BGP同步通过控制BGP表项是否是“最佳”路由来完成其功能。需要记住的是,仅当BGP表中的路由是“最佳”路由时,才能将该路由宣告给BGP对等体。BGP同步机制通过如下方式来确定最佳路由问题:
关键
不将BGP表中的iBGP路由视为“最佳”路由,除非通过IGP学到了完全相同的前缀,并且该前缀目前位于路由表中。
从本质上来说,BGP同步机制为路由器提供了一种了解AS内部非BGP路由器是否有能力将数据包路由到指定前缀的方法。需要注意的是,该路由必须是从IGP学到的路由,因为R6上的静态路由无法为其提供其他路由器(如R8)是否已经学到或未学到该路由的任何提示信息。再次以图1-7为例,R6通过RIP学到这些前缀之后,RIP会将这些路由安装到IP路由表中,此时R6的同步机制就可以将BGP表中从BGP学到的这些相同前缀视为最佳路由的候选路由,如果被选为最佳路由,那么R6就可以将这些BGP路由宣告给R1。
例1-13从R6的角度显示了路由黑洞问题。例中的R6利用BGP子命令no synchronization禁用了BGP同步机制。例1-13的后半部分则显示了R7将BGP路由重分发到IGP之后的R6操作情况(此时R6已经启用了BGP同步机制)。
例1-13 路由黑洞(禁用同步)与解决方案(启用同步)
! R6 has a "best" BGP route to 21.0.0.0/8 through R7 (7.7.7.7), but a trace! command shows that the packets are discarded by R8 (10.1.68.8).R6# show ip bgp | begin Network Network Next Hop Metric LocPrf Weight Path* 21.0.0.0 172.16.16.1 0 123 45 i*>i 7.7.7.7 0 100 0 45 i* 22.2.2.0/24 172.16.16.1 0 123 45 i*>i 7.7.7.7 0 100 0 45 iR6# trace 21.1.1.5Type escape sequence to abort.Tracing the route to 21.1.1.5 1 10.1.68.8 20 msec 20 msec 20 msec 2 10.1.68.8 !H * !H! R7 is now configured to redistribute BGP into RIP.R7# conf tEnter configuration commands, one per line. End with CNTL/Z.R7(config)# router ripR7(config-router)# redist bgp 678 metric 3! Next, R6 switches to use sync, and the BGP process is cleared.R6# conf tEnter configuration commands, one per line. End with CNTL/Z.R6(config)# router bgp 678R6(config-router)# synchronizationR6(config-router)# ^ZR6# clear ip bgp *! R6’s BGP table entries now show "RIB-failure," a status code that can mean! (as of some 12.2T IOS releases) that the prefix is known via an IGP. 21.0.0.0/8! is shown to be included as a RIP route in R6’s routing table. Note also that R6! considers the BGP routes through R7 as the "best" routes; these are still! advertised to R1.R6# show ip bgpBGP table version is 5, local router ID is 6.6.6.6Status codes: s suppressed, d damped, h history, * valid, > best, i - internal, r RIB-failure, S StaleOrigin codes: i - IGP, e - EGP, ? - incomplete Network Next Hop Metric LocPrf Weight Pathr 21.0.0.0 172.16.16.1 0 123 45 ir>i 7.7.7.7 0 100 0 45 ir 22.2.2.0/24 172.16.16.1 0 123 45 ir>i 7.7.7.7 0 100 0 45 iR6# show ip route | incl 21.0.0.0R 21.0.0.0/8 [120/4] via 10.1.68.8, 00:00:15, Serial0/0.8! R6 considers the routes through R7 as the "best" routes; these are still! advertised to R1, even though they are in a "RIB-failure" state.R6# show ip bgp neighbor 172.16.16.1 advertised-routes | begin Network Network Next Hop Metric LocPrf Weight Pathr>i21.0.0.0 7.7.7.7 0 100 0 45 ir>i22.2.2.0/24 7.7.7.7 0 100 0 45 i注:
如果IGP是OSPF,那么BGP同步机制还有一些古怪的要求:如果宣告前缀的路由器的OSPF RID与宣告相同前缀的BGP路由器的RID数值不同,那么同步机制不允许BGP将该路由器视为最佳路由。虽然OSPF与BGP使用相同的优先级及规则来选择自己的RID,但是使用了同步机制之后,对于将BGP重分发到OSPF的路由器来说,最好将其OSPF和BGP的RID显式配置为相同值。
2.禁用同步并在AS内的所有路由器上运行BGP解决路由黑洞的第二种方法就是简单地利用BGP将所有从BGP学到的前缀都宣告给AS中的所有路由器。这样一来,所有的路由器都能知道这些前缀,从而可以安全地关闭同步机制。但是该解决方案的缺点是需要在所有路由器上都引入BGP,而且要求每对路由器之间都必须建立iBGP邻居连接(如果AS中有N台路由器,那么就需要建立N(N-1)/2条邻居连接)。对于大型自治系统来说,这样做会存在大量对等连接,从而严重影响BGP的性能及收敛时间。由于BGP不会将iBGP路由(从iBGP对等体学到的路由)宣告给其他iBGP对等体,因而BGP要求在AS内部建立全网状的iBGP对等连接。虽然该要求能够避免路由环路,但是也带来了全网状iBGP对等连接问题(否则只有部分iBGP对等体能够学到所有前缀)。
BGP提供了两种有效工具(联盟和路由反射器)来减少AS内的对等连接数量,同时还能预防路由环路并允许所有路由器都学到所有前缀。下面将逐一介绍这两种工具。
3.联盟
根据RFC 5065的定义,可以将部署BGP联盟(confederation)机制的AS划分为多个联盟子自治系统,并将AS内的每台路由器都划分到其中的一个联盟子自治系统中。位于同一个Sub-AS(Sub-Autonomous System,子自治系统)中的对等体是联盟iBGP对等体(confederation iBGP peers),位于不同Sub-AS中的路由器是联盟eBGP对等体(confederation eBGP peer)。联盟可以将路由传播给所有路由器,而不需要在整个AS内建立全网状的对等连接。为此,可以在一定程度上将联盟eBGP对等连接视为真正的eBGP对等体。在Sub-AS内部,联盟iBGP对等体之间必须建立全网状连接,因为它们与普通的iBGP对等体操作特性完全相同,即联盟iBGP对等体之间不会相互宣告iBGP路由。联盟eBGP对等体与eBGP对等体相似,因为联盟eBGP对等体可以将从联盟Sub-AS学到的iBGP路由宣告给其他联盟Sub-AS。
联盟利用AS_PATH PA来防止在联盟AS内部产生环路,联盟内的BGP路由器负责将Sub-AS添加到AS_PATH中并作为AS_PATH字段的一部分,称为AS_CONFED_SEQ(AS_PATH最多包含四个组件[称为字段]:AS_SEQ、AS_SET、AS_CONFED_SEQ以及AS_CONFED_SET。有关AS_SEQ和AS_SET的详细信息可参见前面的“手动汇总与AS_PATH路径属性”一节)。
注:
术语AS与Sub-AS指的是自治系统与子自治系统的概念,ASN与Sub-ASN指的则是实际使用的AS号。
与AS_SEQ和AS_SET能够避免自治系统间环路一样,AS_CONFED_SEQ和AS_CONFED_SET也能避免在联盟自治系统内部出现环路。联盟eBGP对等体在将iBGP路由宣告给其他Sub-AS之前,该路由器必须确保目的Sub-AS不在AS_PATH AS_CONFED_SEQ字段中。以图1-8为例,Sub-ASN 65001中的路由器学到一些路由之后将这些路由宣告给Sub-ASN 65002和65003,然后这两个Sub-ASN中的路由器又将这些路由宣告给对方,但是由于AS_CONFED_SEQ(标注在图中)的缘故,这两个Sub-ASN中的路由器始终不会将这些路由宣告给Sub-ASN 65001中的路由器。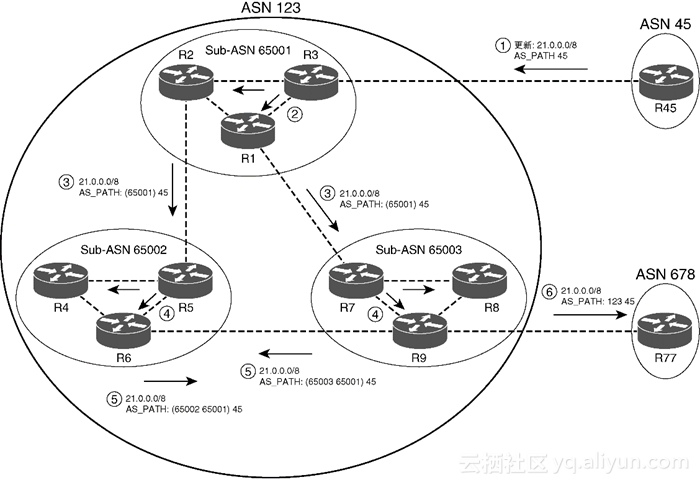
图1-8给出了一个非常详细的联盟AS_PATH案例,图中带圆圈的数字标识的步骤如下。
第1步:R45注入并通过eBGP将路由21.0.0.0/8宣告给AS 123,该路由的AS_PATH为45。
第2步:R3通过自己的两条iBGP连接宣告该前缀,但是根据Sub-AS内部的iBGP规则,R1与R2之间不会相互宣告该前缀。
第3步:Sub-AS 65001中的路由器按照eBGP规则将21.0.0.0/8宣告给它们的联盟eBGP对等体,但是首先要将自己的Sub-ASN添加到AS_PATH的AS_CONFED_SEQ字段中(这部分AS_PATH显示在show ip bgp命令输出结果中的括号内[如图1-8所示])。
第4步:其他两个子自治系统均重复第2步所描述的相同操作。
第5步:R6和R9将各自的ASN添加到AS_CONFED_SEQ中之后,会将该路由宣告给对方。
第6步:R9删除了AS_PATH中的Sub-AS信息之后,通过真正的eBGP连接宣告该前缀。
完成上述步骤之后,ASN 123中的所有路由器都将学到前缀21.0.0.0/8,而且ASN 678(对于本例来说就是R77)也将学到该相同前缀的路由,并且该路由工作正常,不存在路由黑洞问题。从ASN 678的角度来看,它看到的路由实际上就是经ASN 123和45的路由。需要注意的是,Sub-AS 65002和65003中的路由器不会将该前缀宣告回Sub-AS 65001,因为AS 65001已经位于联盟AS_PATH中了。
本例的Sub-AS 65001、65002、65003并不是随便选择的。ASN 64512~65535属于私有ASN,如果不需要将ASN宣告给Internet或其他自治系统,那么就可以使用这些私有ASN。联盟使用了私有ASN之后就可以避免如下问题:假如Sub-AS 65003使用的是ASN 45,由于AS_PATH环路校验会检查整个AS_PATH,因而根本就无法将图1-8中的前缀宣告给Sub-AS 45,也就无法宣告给ASN 678。使用私有ASN就可以避免出现该问题。
联盟的技术要点如下。
关键
Sub-AS内部必须建立全网状连接,这是因为Sub-AS内部需要满足所有的iBGP规则。
联盟eBGP连接在宣告iBGP路由的时候与常规eBGP连接完全相同(只要AS_PATH校验结果显示该路由宣告不会产生环路即可)。联盟eBGP连接在TTL(Time to Live,生存时间)的处理上也与常规eBGP连接完全相同,这是因为所有数据包都默认使用TTL 1(可以通过neighbor ebgp-multihop命令更改TTL)。联盟iBGP连接在各种问题的处理上与常规iBGP连接完全一致,如默认不更改NEXT_HOP。路由器基于最短AS_PATH选择最佳路由时,联盟AS不在AS_PATH的长度计算之列。由于联盟路由器会从发送到联盟外部的更新消息的AS_PATH中删除联盟ASN,因而其他路由器并不知道联盟的存在。4.配置联盟虽然只要在本章前面介绍过的命令之外增加少量命令即可完成联盟配置工作,但是将网络迁移到联盟机制却非常麻烦,这是因为此时不是在router bgp命令中配置真实的ASN,而是在BGP子命令bgp confederation identifier中配置真实的ASN,因而迁移过程会导致一条或多条路由不可用。表1-10列出了常见的联盟命令及其功能。关键

例1-14给出了图1-9所示拓扑结构的简单配置示例。

关键
只有充当RR的路由器才使用修改后的操作规则,其他路由器(包括客户端与非客户端)甚至都不知道RR的存在,而且也不改变操作规则。表1-11列出了RR的操作规则,其操作规则与RR从哪种类型的BGP对等体收到前缀有关。表中列出了可以学习前缀的源端以及RR将前缀信息反射给哪些类型的路由器。
关键
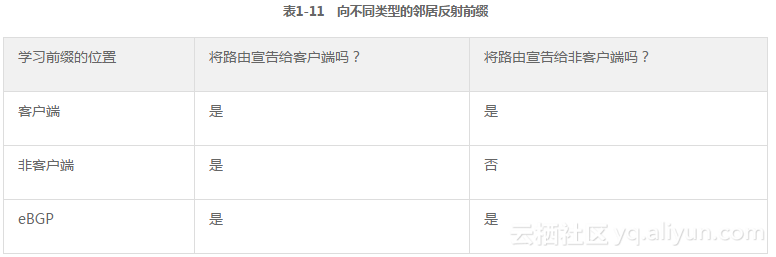
有一种情况RR不会反射路由,即RR从非客户端路由器收到路由后,RR不会将该路由反射给其他非客户端。其原因在于RR与非客户端及eBGP邻居之间的操作规则完全遵从常规的iBGP对等体规则。也就是说,RR不会将学自iBGP的路由反射给其他非客户端iBGP对等体。RR操作规则差异与客户端何时向RR发送前缀或者RR何时决定将前缀反射给客户端有关。
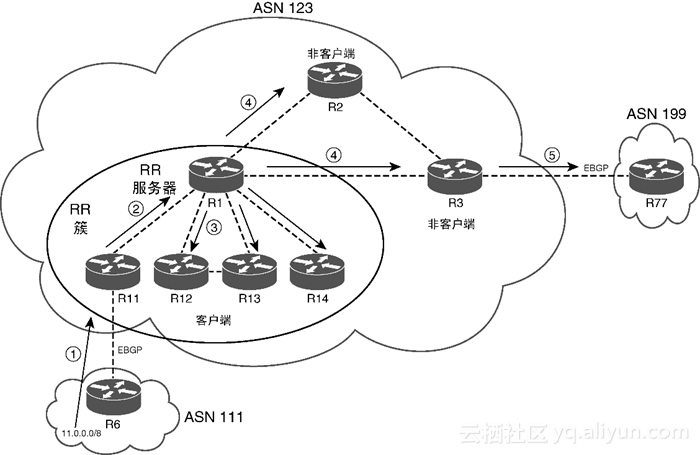
一个(或多个)RR及其客户端可以组成一个RR簇(cluster),采用RR的BGP设计方案允许:
多个RR位于同一个RR簇中;
多个RR簇(虽然多个RR簇仅在拥有物理冗余时才有意义)。在多簇场景下,每个簇至少要有一个RR必须与其他簇中的至少一个RR建立对等连接。通常在所有的RR之间都应建立直接对等连接,从而在所有的RR之间建立全网状的RR iBGP对等连接。此外,如果有些路由器是非客户端路由器,那么也必须将这些路由器包含在RR的全网状连接中(如图1-11所示)。图中的每台RR不但与其他簇中的RR建立了全网状连接,而且也与非客户端路由器建立了全网状连接。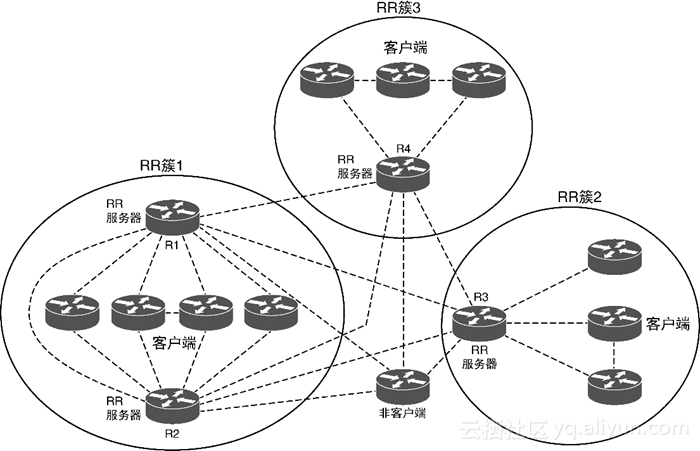
对比表1-11和图1-11后可以看出,这种设计方案不但可能存在路由环路,而且可能性非常大。不过,RR可以通过以下工具来有效防止路由环路。
关键
CLUSTER_LIST:RR在发送更新消息之前,会将自己的簇ID添加到称为CLUSTER_LIST的BGP PA中,因而RR收到更新消息之后,如果在其中发现了自己的簇ID,那么就会丢弃接收到的前缀。与联盟的AS_PATH相似,该特性可以帮助RR避免在簇之间产生环回宣告。
ORIGINATOR_ID:该PA列出的是将路由宣告到AS中的第一个iBGP对等体的RID。如果路由器在接收到的路由中发现ORIGINATOR_ID是自己的BGP ID,那么就不会使用或传播该路由。仅宣告最佳路由:仅当RR认为指定路由是其BGP表中的“最佳”路由时,RR才反射该路由。该规则进一步限制了RR所要反射的路由(与联盟相比,该规则还有一个明显好处,那就是路由器一般只能看到较少的路由,特别是无用、冗余的路由)。例1-15给出了一个使用RR的简单示例。该设计方案包括两个簇,有两个RR(R9和R2)和两个客户端(R1和R3)。此时的前缀传播过程如下(如图1-12所示)。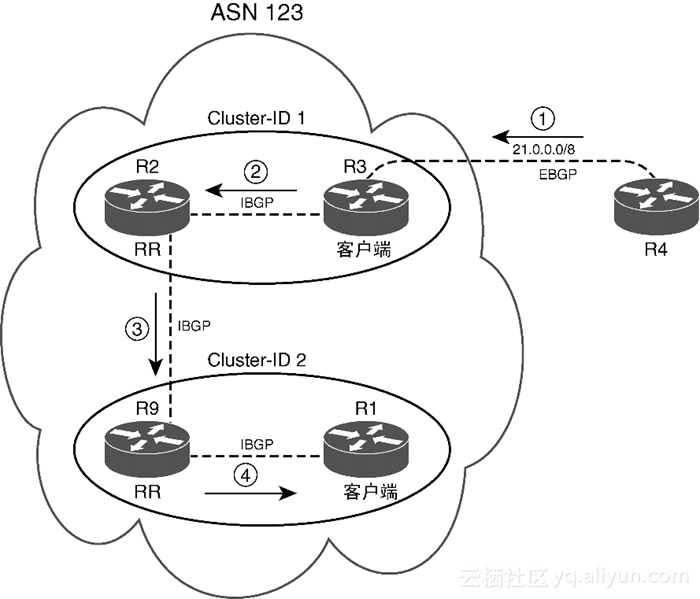
第1步:R3通过eBGP从AS 45(R4)学到前缀21.0.0.0/8。
第2步:R3通过iBGP将该前缀宣告给R2(使用标准规则)。
第3步:R2(RR)从RR客户端收到前缀之后,通过iBGP将该路由反射给R9(对R2来说是非客户端)。
第4步:R9(RR)从非客户端收到iBGP路由之后,将该路由反射给R1(其RR客户端)。
例1-15 AS 123的RR配置:两个RR和两个客户端
! R3 Configuration. The RR client has no overt signs of being a client; the! process is completely hidden from all routers except RRs. Also, do not forget! that one of the main motivations for using RRs is to allow sync to be disabled.router bgp 123 no synchronization neighbor 2.2.2.2 remote-as 123 neighbor 2.2.2.2 update-source Loopback1 neighbor 2.2.2.2 next-hop-self neighbor 4.4.4.4 remote-as 45 neighbor 4.4.4.4 ebgp-multihop 255 neighbor 4.4.4.4 update-source Loopback1! R2 Configuration. The cluster ID would default to R2’s BGP RID, but it has been! manually set to "1," which will be listed as "0.0.0.1" in command output. R2! designates 3.3.3.3 (R3) as a client.router bgp 123 no synchronization bgp cluster-id 1 neighbor 3.3.3.3 remote-as 123 neighbor 3.3.3.3 update-source Loopback1 neighbor 3.3.3.3 route-reflector-client neighbor 9.9.9.9 remote-as 123 neighbor 9.9.9.9 update-source Loopback1! R9 Configuration. The configuration is similar to R2, but with a different! cluster ID.router bgp 123 no synchronization bgp router-id 9.9.9.9 bgp cluster-id 2 neighbor 1.1.1.1 remote-as 123 neighbor 1.1.1.1 update-source Loopback2 neighbor 1.1.1.1 route-reflector-client neighbor 2.2.2.2 remote-as 123 neighbor 2.2.2.2 update-source Loopback2 no auto-summary! The R1 configuration is omitted, as it contains no specific RR configuration,! as is the case with all RR clients.! The 21.0.0.0/8 prefix has been learned by R3, forwarded over iBGP as normal to! R2. Then, R2 reflected the prefix to its only other peer, R9. The show ip bgp! 21.0.0.0 command shows the current AS_PATH (45); the iBGP originator of the! route (3.3.3.3), and the iBGP neighbor from which it was learned ("from! 2.2.2.2"); and the cluster list, which currently has R2’s cluster (0.0.0.1).! The next output is from R9.R9# show ip bgp 21.0.0.0BGP routing table entry for 21.0.0.0/8, version 3Paths: (1 available, best #1, table Default-IP-Routing-Table)Flag: 0x820 Advertised to update-groups: 2 45 3.3.3.3 (metric 2300416) from 2.2.2.2 (2.2.2.2) Origin IGP, metric 0, localpref 100, valid, internal, best Originator: 3.3.3.3, Cluster list: 0.0.0.1! RR R9 reflected the prefix to its client (R1), as seen next. Note the changes! compared to R9’s output, with iBGP route being learned from R9 ("from 9.9.9.9"),! and the cluster list now including cluster 0.0.0.2, as added by R9.R1# sho ip bgp 21.0.0.0BGP routing table entry for 21.0.0.0/8, version 20Paths: (1 available, best #1, table Default-IP-Routing-Table) Not advertised to any peer 45 3.3.3.3 (metric 2302976) from 9.9.9.9 (9.9.9.9) Origin IGP, metric 0, localpref 100, valid, internal, best Originator: 3.3.3.3, Cluster list: 0.0.0.2, 0.0.0.1 转载地址:http://llddx.baihongyu.com/